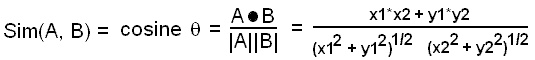최근 2개월간 나의 최대 관심사는 띄어쓰기이다.
물런 2개월 이전에도 관심을 가지고 논문 몇편을 보긴 했었다. 하지만 회사에서나 집에서나 대부분의 시간을 이문제에 대해서 생각한건 최근 2개월 동안이었던것 같다.
논문을 쓰기 위한 고민이 아니었기 때문에 고민의 가지수는 더 많아졌고,
그 고민들중 두가지는 필드에서 사용가능한 퀄리티와 속도였다.
이런 프로그래을 개발하는 것은 마치 두마리 토끼를 동시에 잡는 것과 비슷한 느낌의 일이었다.
보통 한국어 띄어쓰기의 경우 손쉽게 생각해 볼수 있는 방법이 통계적 방법을 이용하는 것이고 그중에서도 속도나 데이터 부족 문제를 피하기 위해서 바이그램(음절)을 사용하는 경우가 제일 쉬운 접근 방법일 것이다.
우선 바이그램 정보를 어떻게 추출하는지 살펴보면
바이그램으로 데이터를 트레이닝한다고 할때에도 여러가지 방법이 있을수 있다. 외부에 보여지는 두개의 음절이외에 어떤 정보를 추가적으로 담을 것인가..
트라이 그램보다는 바이그램 정보가 작고, 정보량도 부족하기 때문에 바이그램이 담을수 있는 최대치의 정보를 담기 위해서 노력했다.
예를 들면
[띄어쓰기가 더 쉽다 ]
이런 문장이 있다고 할때 여기서 바이그램을 추출하면
(공백 대신 => _ )
[ 띄어], [어쓰], [쓰기], [가가_], [가_더], [_더_쉽], [쉽다_]
위와 같이 추출된다. (꺽쇠 괄호 안의 음절수는 항상 2이다)
[_더_쉽]의 경우 음절 바이그램이지만 총 4개의(공백 포함) 정보를 담고 있다.
이처럼 바이그램이지만 비교적 정보를 많이 담았다고 생각했지만
아래의 예제와 같은 경우를 만나는 순간 바이그램의 한계를 직감할수 있었다.
ex> [먹는데이가아파요]
위 문자열에 대한 바이그램 정보를 다음과 같다.
먹는 2042 5848 0 1 8388 15699 8 21
는데 179998 187 53367 90 328859 309 113573 153
데이 73361 73171 76141 29836 10477 949 9636 307
이가 5692 2605 223119 25558 115146 3166 705 18
가아 2112 85 153333 331 4 1 166 0
아파 68547 166835 2413 213 6551 1309 17 2
파요 467 2 109 0 33 0 0 0
위의 테이블에 대해서 간단하게 설명하명
[먹는] 라는 바이그램 음절은
[먹는] 앞,중앙,뒤 공백없이 사용된 횟수가 2042 번이다.
[_먹는] 앞부분에 공백, 중간,뒤 공백없이 사용된 횟수가 5848 이다.
[먹_는] 중간에만 공백이 들어간 횟수가 0 번이다.
[_먹_는] 앞과 중간에 공백이 들어간 횟수가 1 번이다.
[먹는_] 뒤에 공백이 들어간 횟수가 8388 이다.
[_먹는_] 앞과 뒤에 공백이 들어간 횟수는 15699 이다
[먹_는_] 중간과 뒤에 공백이 들어간 횟수는 8이다.
[_먹_는_] 앞,중간,뒤 모두에 공백이 들어간 횟수는 21이다.
처음 시작은 공백이 있다고 가정한다.
다시 말하면 [_먹는데이가아파요_]와 같은 문장이 입력으로 들어왔다고 가정한다.
그렇게 되면
처음 시작은
[_먹는] 5848
[_먹_는] 1
[_먹_는_] 21
[_먹는_] 15699
이정도의 경우의 수가 생길것이다.
이중에서 가장 빈도가 높은 것은 [_먹는_] 이 된다.
문서 상에서는 "먹는 방법" 먹는 이유" 먹는 자세" 등과 같은 형태가 많기 때문에 당연히 [_먹는_]과 같은 형태가 고빈도로 나타난다.
그런데 우리는 [_먹는_]을 선택하면 안된다.
왜냐하면 우리가 원하는 것은 [_먹는_]이 아니고 [_먹는] 이어야 다음 [는데]를 시작할수 있기 때문이다.
시작이 틀리면 다음에 오는 분석에 영향을 미치기 때문에 우리는 다음단계의 확률 더나아가 다다음단계의 확률까지 계산을 해야할지도 모른다.
현재 상태에서는 일단 [_먹는_]이 확률이 가장 높기 때문에 이 다음 확률이 어떻게 되는지 살펴볼 필요가 있다.
다음 확률 값은 "는데"
는데 179998 187 53367 90 328859 309 113573 153
[는데] 179998
[_는데] 187
[는_데] 53367
[_는_데] 90
[는데_] 328859
[_는데_] 309
[는_데_] 113573
[_는_데_] 153
다행히 [는데_]의 빈도가 328859 로 가장 높다.
그러면 [는데_]가 될수 있도록 하려면 [_먹는]이 선택되어야 한다.
두가지 경우의 수만 가지고 판단을 하면
-
[_먹는] [는데_] => [_먹는데_] => 5848 + 328859 = 334,707
-
[_먹는_][는_데] => [_먹는_데] => 15699 + 113573 = 129,272
이와 같은 방식으로 마지막 음절까지 최대 빈도값을 추적해 가면
먹는데/이가/아파요 라는 문장을 얻을수 있을 것이다.
다음 포스트에서는 바이그램으로는 절대 처리할수 없는 예에 대해서 설명하겠다.
이 글은 스프링노트에서 작성되었습니다.

)
)
 invalid-file
invalid-file
 LSA를 이용한 내용기반 검색엔진 시스템.pdf
LSA를 이용한 내용기반 검색엔진 시스템.pdf