htttp://www.ddj.com/windows/184410528
당신이 문자열을 저장 할려고 할때 당신은 어떤 data structure를 사용하는가
존과 로버트는 binary search trees의 공간 효율과 digital tries의 시간 효율을 결합한 ternary search trees로 시작할 것을 제안했다.
--
당신이 문자열을 저장 할려고 할때 당신은 어떤 data structure를 사용하는가
당신은 문자열을 array에 뿌리는 해쉬테이블을 사용할수도 있다.
이방법은 접근이 빠르다. 하지만 상대적인 순서에 대한 정보를 잃어버린다.
다른 방법은 문자열을 순서대로 저장하고 비교적 빠른 binary search trees를 사용하는것이다.
아니면 당신은 가볍고 빠르지만 공간을 많이 소비하는 digital search tries를 사용하는 것이다.
이 기사에서 우리는 binary search trees의 공간 효율과 digital tries의 시간 효율을 결합한ternary(3-wary) search trees를 실험한다.
일반적인 검색 문제에서 이방법은 해슁을 하는 방법보다 빠르다. 그리고 다양한 기능들을 제공한다.
Ternary searches은 해슁보다 빠르고 powerful하다.
우리는 1997년 심포지엄에서 ternary search trees에 대해서 설명하였다.
아래 그림은 binary search tree로 2개의 알파벳을 갖는 12개의 노드들을 표현한다.
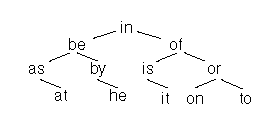
모든 노드에 좌측에는 자신보다 작은 값을 우측에는 큰값을 갖는다.
검색은 root에서 시작한다.
"ON"이라는 단어를 찾기 위해서 우리는 먼저 "IN"과 비교하고 오른쪽 노드로 이동한다.
그리고 다시 "OF"와 비교하여 우측 노드로 이동하고 다시 "OR"과 비교하여 좌측의 "ON" 을 검색한다.
모든 비교과정에서 두단어의 모든 캐릭터에 접근해야 한다.
Digital search tries는 문자열의 캐릭터를(1byte)를 저장한다.
아래 그림은 12개 단어셋에 대해서 Digital search tries로 표현되었다.
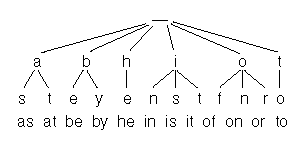
각 입력 문자열은 각 노드를 표현하는 노드 바래 아래에 보여진다.
트리의 각 노드는 26개의 서브 노드를 가지고 있다.
검색은 매우 빠르다. 만약 "is"를 검색한다면 root에서 시작하여 'i'노드로 이동하고 다시 's'로 이동한다. 이것으로 검색이 끝난다.
모든 노드에서 우리는 array에 직접 접근한다.
불행히도 search tries는 엄청난 공간을 요구한다.
노드마다 26개의 branch,를 가지기 때문에 104byte의 공간을 요구하고 256개의 노드는 kilobyte를 소비한다.
8개의 노드 34000개의 캐릭터를 표현하기 위해서는 megabyte이상의 메모리를 필요로 한다.
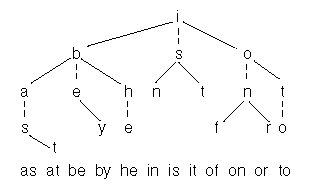
binary search trees의 공간 효율과 digital tries의 시간 효율을 결합한ternary(3-wary) search trees는 캐릭터 단위로 진행하는점에 있어서 tries와 비슷한다.
각노드는 3개의 children을 가짐으로써 공간적인 효율을 기함으로써 binary search trie와 비슷하다.
검색시 비교는 노드에서 문자열의 한 캐릭터와 현재 키릭터를 비교한다.
만약 검색할 캐릭터가 작으면 좌측으로 분기하고 검색할 캐릭터가 크다면 우측으로 분기한다.
만약 같다면 middle child로 이동하여 검색하는 문자의 다음 글자로 다시 위의 작업을 진행한다.
아래그림은 12개의 단어셋을 가지는 balanced ternary search tree이다.
좌우 child는 실선으로 equal pointer는 점선으로 펴현했다.
입력 문자열의 터미널 노드에 표시했다.
'is' 검색시 루트에서 시작하여 'i' 노드에서 's'로 equal child로 이동한다.그리고 's'를 비교함으로써 검색이 종료된다.
--- continued ---

)
)
)
)




